Was ist das fundamentale Konzept von objektorientierter Programmierung? Vielleicht denken Sie an Vererbung, Kapselung, Polymorphie oder Abstraktion. Natürlich sind all diese Konzepte relevant für OOP, aber ein zentrales Konzept, das oft übersehen wird, sind Nachrichten bzw. Ereignisse. Alan Kay, der als Pionier der objektorientierten Programmierung gilt, hat diesen Aspekt Problem einmal wie folgt beschrieben:
I thought of objects being like biological cells and/or individual computers on a network, only able to communicate with messages (so messaging came at the very beginning – it took a while to see how to do messaging in a programming language efficiently enough to be useful).
Alan Kay, https://www.purl.org/stefan_ram/pub/doc_kay_oop_en
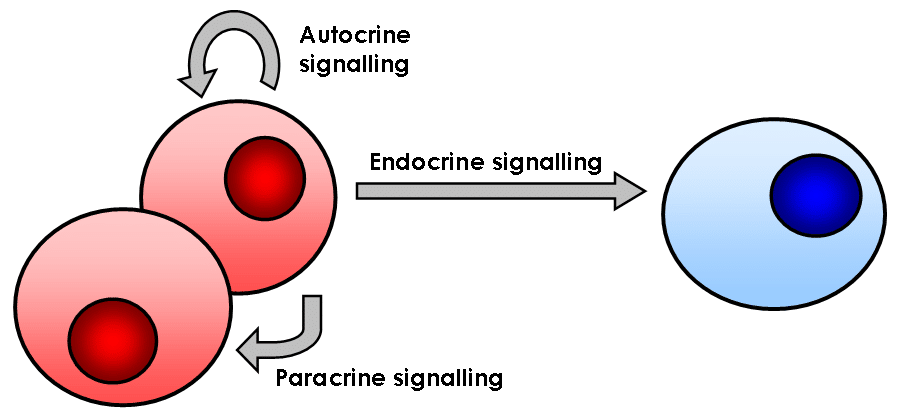
Auch beim Einsatz von Cloudtechnologien kommen Ereignissen eine ebenso wichtige Rolle zu. Durch ereignisgetriebene Architekturen können modulare, lose gekoppelte und skalierbare System aufgebaut werden, die Änderungen und Evolution über Zeit unterstützen.
In diesem Artikel werden wir das Thema der ereignisgetriebenen Architekturen (engl. Event-Driven Architecture, oder kurz EDA) intensiv behandeln. Wir sehen uns die Konzepte, Vorteile und Herausforderungen beim Einsatz von EDA an, lernen die wichtigsten Patterns zur Umsetzung kennen und besprechen typische Einsatzzwecke von ereignisgetriebenen Architekturen.
Grundkonzepte von ereignisgetriebenen Architekturen
Wie der Name vermuten lässt, dreht sich bei EDA alles um Ereignisse oder Events. Ein Ereignis ist der Eintritt einer Zustandsänderung einer Entität. Ereignisse werden typischerweise über Nachrichten (engl. Messages) ausgetauscht. Typische Beispiele für Ereignisse sind:
- Benutzerregistrierung: Wenn sich ein neuer Benutzer für ein System registriert, wird ein Ereignis erzeugt. Andere Systeme wie ein Customer Relationship Management oder ein Tool für Marketingautomatisierung hören auf dieses Ereignis und führen entsprechende Aktion aus.
- E-Commerce: Neue Bestellungen können Ereignisse auslösen, auf die Zahlungsverarbeitung, Inventarhaltung oder Versandwesen reagieren können.
- Bounded Context: Wenn ein System nach Bounded Contexts laut Domain-Driven Design zerlegt wurde, können die so entstandenen Domänen über Ereignisse lose gekoppelt werden.
- CQRS: Bei getrennten Lese- und Schreibdatenbanken kann das Command-Model ein Event erzeugen, welches das Query-Model zur Synchronisation liest.
Häufig werden die Begriffe „Ereignis“ und „Nachricht“ synonym verwendet, streng genommen wird aber die Nachricht als Reaktion eines Ereignisses erzeugt. Der Einfachhalt halber werde ich diese Begriffe auch synonym verwenden. Wie es richtig ist, haben wir ja jetzt geklärt 😉.
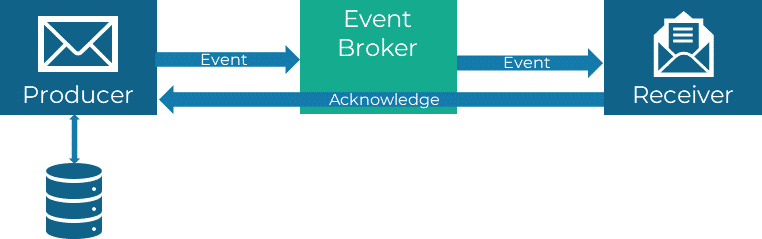
Die Ereignisse werden von einem Produzenten erzeugt und über den Event-Broker zum Empfänger geschickt. Durch den Broker sind Produzent und Empfänger voneinander entkoppelt. Eine nähere Beschreibung der typischen EDA-Komponenten finden Sie weiter unten.
Kommuniziert wird grundsätzlich asynchron, d. h. das Senden und Empfangen der Daten geschieht zeitlich versetzt und ohne zu blockieren. Der Produzent sendet seine Nachricht und wartet nicht auf eine Antwort, wie es bei synchroner Kommunikation der Fall wäre.
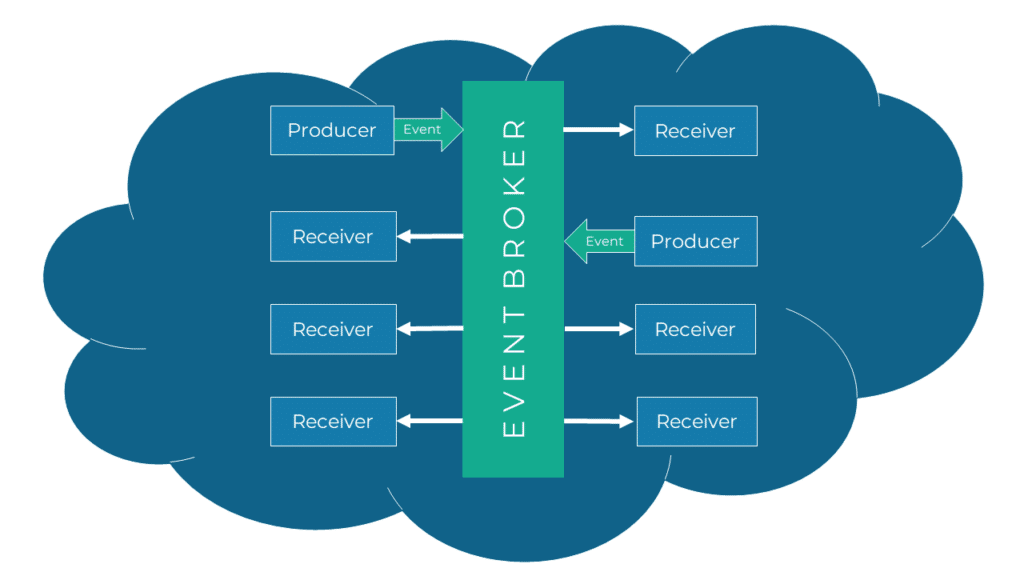
Vorteile
- Durch den Einsatz eines Brokers kann in einer EDA Produzent und Empfänger sowohl örtlich als auch zeitlich entkoppelt werden. Ebenso wird eine technologische Entkoppelung erreicht, da Produzent und Empfänger in verschiedenen Technologien implementiert sein können.
- Ereignisse werden sofort registriert, wenn sie auftreten. Es fallen keine Wartezeiten an, wie sie bei Polling entstehen würden.
- EDAs haben eine hohe Skalierbarkeit. Durch den ereignisgetriebenen Ansatz kann insbesondere das horizontale Skalieren durch Hinzufügen weiterer Instanzen eines Dienstes vereinfacht werden. Ebenso ist eine Parallelverarbeitung von Aufgaben einfacher möglich.
- Durch die technologische Entkoppelung kann die Flexibilität des Systems erhöht werden. Anpassungen können schrittweise durchgeführt werden, ohne das gesamte System ändern zu müssen.
- In Cloud-basierten EDAs können Serverless-Dienste wie AWS Lambda oder Azure Functions sehr gut umgesetzt werden. Das kann sich positiv auf die Gesamtkosten des Systems auswirken.
Als Folgerung dieser Vorteile sind ereignisgetriebene Systeme sehr anpassungsfähig und unterstützen Veränderungen im System. Neue Empfänger können hinzugefügt werden, ohne das am Produzenten Änderungen vorgenommen werden müssen. Ebenso können dieselben Ereignisse von unterschiedlichen (und neuen) Produzenten erzeugt werden.
Herausforderungen
Natürlich sind EDAs nicht ein Allheilmittel für alle Problemstellungen. Wie bei jedem Architekturansatz gibt es auch bei ereignisgetriebenen Architekturen Herausforderungen, die behandelt und abgewogen werden müssen:
- Generell ist die Komplexität einer ereignisgetriebenen Architektur höher als bei konventionellen Architekturen. Es müssen zusätzliche Komponenten wie der Event Broker sowie Patterns und Code im Umgang mit den Ereignissen hinzugefügt werden. Das „Denken in Ereignissen“ kann ebenso zu zusätzlichem Aufwand führen.
- Insbesondere Monitoring und Debugging kann herausfordernd werden, wenn Ereignisse und Fehler über komplexe Eventketten nachvollzogen werden müssen.
- Durch die asynchrone Kommunikation besteht keine Garantie auf Antwortzeiten. Je nach konkretem Anwendungsszenario kann dies ein Problem sein. In der Regel ist ein direkter Funktionsaufruf schneller als eine Kommunikation über einen Event Broker.
- Bei umfangreichen Ereignisketten kann die Orchestrierung der einzelnen Teilnehmer schwierig werden.
Komponenten einer EDA
Eine EDA besteht im wesentlichen aus drei Komponenten:
- Produzent: Erzeug das Ereignis
- Broker: Leitet das Ereignis weiter
- Empfänger: Empfängt das Ereignis.
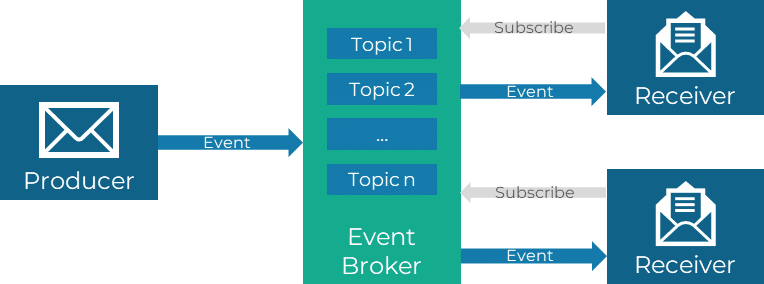
Der Produzent ist für das Generieren und Auslösen von Ereignissen verantwortlich. Diese Ereignisse sind Zustandsänderungen, die beispielsweise durch Benutzeraktionen, Systemereignisse oder externe Inputs ausgelöst werden. Der Broker fungiert als Vermittler und nimmt die Ereignisse vom Produzenten entgegen, bevor er sie an die entsprechenden Empfänger weiterleitet. Dabei kann der Broker zusätzliche Aufgaben wie die Sicherstellung der Zuverlässigkeit oder auch die Transformation von Ereignisdaten übernehmen. Für ein Ereignis können mehrere Empfänger existieren, die auf die empfangenen Ereignisse reagieren und entsprechende Aktionen ausführen. Durch diese Aufteilung der Verantwortlichkeiten wird eine lose Kopplung zwischen den Komponenten ermöglicht, was Skalierbarkeit, Flexibilität und Wartbarkeit der Architektur fördert.
Event-Broker
Der Event-Broker ist eine entscheidende Komponente in einer EDA, da er als Vermittler fungiert und die nahtlose Übertragung von Ereignissen zwischen verschiedenen Teilen des Systems ermöglicht. Seine Funktion ist es, die Ereignisse entgegenzunehmen, zu puffern und an die entsprechenden Empfänger weiterzuleiten. Dabei kümmert sich der Broker um die sichere Zustellung, die Transformation von Ereignisdaten oder die Überwachung der Nachrichtenflüsse.
Technisch gibt es verschiedene Ansätze, den Broker umzusetzen. Messaging-Dienste wie Apache Kafka, NATS, RabbitMQ, oder ActiveMQ bieten Funktionen, die typischerweise von Event-Brokern benötigt werden. Sie ermöglichen die Erstellung von Queues, in denen Ereignisse gespeichert und verwaltet werden können. Produzenten können Ereignisse in diese Warteschlangen senden, und Empfänger können sich registrieren, um Ereignisse aus den Warteschlangen zu lesen und zu verarbeiten. Darüber hinaus bieten viele Messaging-Dienste erweiterte Funktionen wie Nachrichtenrouting, Nachrichtenfilterung, Nachrichtenpriorisierung und Fehlerbehandlung, die für die Implementierung einer robusten und skalierbaren ereignisgesteuerten Architektur von Vorteil sind.
Auch bei den meisten Cloud-Anbietern kann man Messaging-Dienste finden, die sich als Event-Broker eignen. Amazon biete Simple Queue Service (SQS) an. Microsoft Azure hat mehrere Dienste im Angebot wie Event Grids, Event Hub und Service Bus. Google verfügt mit Google Cloud Sub/Pub ebenfalls über einen Messaging-Dienst, der als Event-Broker verwendet werden kann.
Netzwerkprotokolle
Auf Protokollebene werden vor allem die beiden Protokolle MQTT und AMQP eingesetzt. Obwohl beide Protokolle auf OSI-Schicht 7 definiert sind, ist MQTT als leichtgewichtiges Protokoll für die Machine-To-Machine-Kommunikation ausgelegt. Es unterstützt lediglich ein Publish-Subscribe-Model für die Kommunikation. Durch seine Leichtgewichtigkeit ist es besonders für Szenarien mit limitierter Bandbreite gut geeignet. Seit 2013 wird MQTT nicht mehr als Akronym genutzt, zuvor konnte es aber als Message Queue Telemetry Transport übersetzt werden. Bekannte Implementierung sind Mosquitto, Azure Event Grid MQTT Broker oder Solace PubSub+.
AMQP (Advanced Message Queuing Protocol) hingegen bietet erweiterte Funktionen wie Queuing, Point-to-Point-Routing und Publish-Subscribe-Routing. Ein Fokus wird auch auf Sicherheitsfunktionen wie Datenverschlüsselung und Policies gelegt. AMQP wird unter anderem von RabbitMQ, ActiveMQ, Azure Service Bus oder Solace PubSub+.
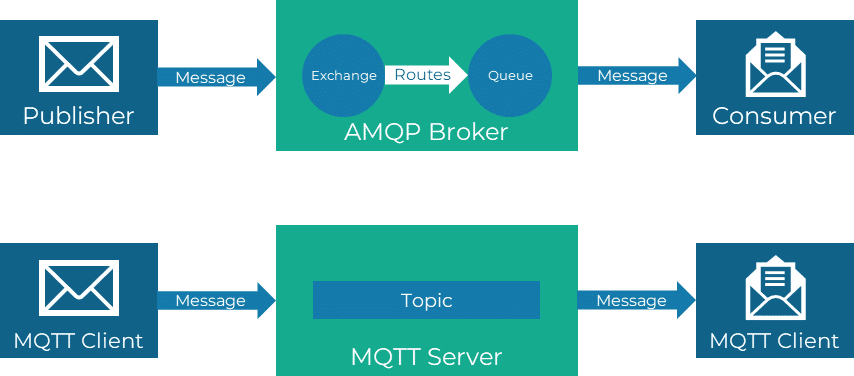
Neben den beiden genannten Protokollen wird beispielsweise noch das Simple Text Orientated Messaging Protocol (STOMP) oder das Constrained Application Protocol (CoAP) verwendet.
Muster
Muster stellen wiederverwendbare Lösungsvorlagen für häufig auftretende Problemstellung dar. Im folgenden beschreibe ich einige hilfreiche und oft verwendete Muster, die im Zusammenhang mit EDA eingesetzt werden können.
Erzeugungsmuster
Erzeugungsmuster werden eingesetzt, um Nachrichten beim Eintreten von Ereignissen zu erzeugen. Es gibt hier verschiedene Ansätze, die in den folgenden Muster beschrieben werden:
Kommunikationsmuster
Über Kommunikationsmuster wird festgelegt, wie der Nachrichtenfluss zwischen Produzent und Empfänger abgebildet ist. Wir sehen uns hierbei vier weitverbreitete Muster an:
Empfangsmuster
Der Empfang der Nachrichten kann über Empfangsmuster gesteuert werden.
Muster zur Fehlerbehandlung
Fehlerbehandlung kommt in verteilten Systemen eine besondere Wichtigkeit zu.
Event Carried State Transfer
Event Carried State Transfer (ECST) ist ein Ansatz in der Softwarearchitektur, der darauf abzielt, den Zustand einer Anwendung durch die Übertragung von Ereignissen zwischen den verschiedenen Komponenten zu verwalten. Im Gegensatz zu anderen Ansätzen, bei denen der Zustand zentralisiert in einer Datenbank oder einem Speicherort gespeichert wird, wird beim ECST der Zustand durch Ereignisse übertragen und von den beteiligten Komponenten selbst verwaltet.
Das Grundprinzip des ECST besteht darin, dass jede Änderung des Zustands einer Komponente als Ereignis erfasst und an andere Komponenten weitergeleitet wird, die davon betroffen sind. Dadurch wird der Zustand dezentralisiert und in Form von Ereignissen durch das System getragen. Jede Komponente kann die Ereignisse empfangen, die für sie relevant sind und entsprechend reagieren, indem sie ihren eigenen Zustand aktualisiert.
Ein wesentlicher Vorteil des ECST besteht darin, dass er die Kopplung zwischen den verschiedenen Komponenten verringert und die Skalierbarkeit und Flexibilität des Systems erhöht. Da der Zustand dezentralisiert ist und durch Ereignisse übertragen wird, können Komponenten unabhängig voneinander entwickelt, bereitgestellt und skaliert werden, ohne dass dies Auswirkungen auf andere Teile des Systems hat.
Ein praktisches Beispiel für die Anwendung des ECST-Musters findet sich in verteilten Systemen, insbesondere in Microservices-Architekturen. Hier können Microservices mithilfe von Ereignissen ihren Zustand untereinander synchronisieren, um konsistente und reaktionsschnelle Anwendungen zu gewährleisten.
Event Streaming
Beim Event Streaming“ werden Ereignisse von verschiedenen Quellen in Echtzeit kontinuierlich erfasst, verarbeitet und analysiert, wodurch ein ständiger Datenstrom entsteht, der als „Event Stream“ bezeichnet wird. Dieser Datenstrom wird dann von verschiedenen Anwendungen, Diensten oder Analysewerkzeugen abonniert, um die Ereignisse in Echtzeit zu verarbeiten und entsprechende Aktionen auszuführen. Dabei können die Ereignisse sowohl strukturierte Daten wie z. B. Benutzeraktionen als auch unstrukturierte Daten wie Logmeldungen oder Sensordaten umfassen.
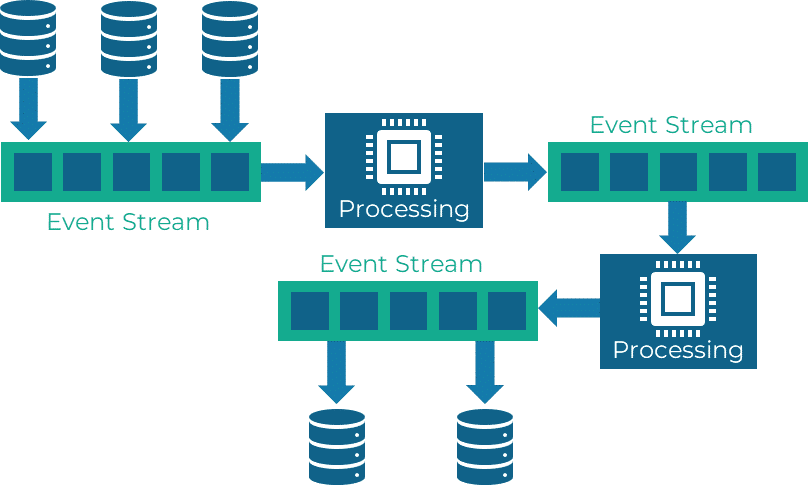
Ein wesentliches Merkmal des Event Streaming ist seine Fähigkeit, große Datenmengen in Echtzeit zu verarbeiten und zu analysieren. Darüber hinaus bietet das Muster eine hohe Skalierbarkeit und Flexibilität, da neue Quellen oder Verarbeitungsschritte einfach hinzugefügt werden können, ohne dass dies die bestehende Infrastruktur beeinträchtigt. Ein bekanntes Beispiel für die Anwendung des Event Streaming ist Apache Kafka, eine verteilte Streaming-Plattform, welche oft für Echtzeitdatenverarbeitung und -analyse eingesetzt wird.
Change Data Capture
Change Data Capture (CDC) ist ein Muster, das darauf abzielt, Änderungen an Daten in Echtzeit zu erfassen und zu verarbeiten. Bei diesem Muster werden Datenbankänderungen kontinuierlich überwacht und erfasst, um sie in einem anderen System oder einer anderen Datenbank zu replizieren oder zu verarbeiten. Dies ermöglicht eine Synchronisierung und Replikation von Daten zwischen verschiedenen Systemen oder Datenbanken in Echtzeit.
Dabei werden alle Änderungen an Daten, wie z. B. das Hinzufügen neue Datensätze, Aktualisierungen oder Löschungen von Daten als Ereignisse erfasst werden, die dann mittels Event-Broker an andere System synchronisiert wird. Dies ermöglicht es, dass die Änderungen in Echtzeit in anderen Systemen reflektiert werden, ohne dass es zu Verzögerungen oder Dateninkonsistenzen kommt.
CDC wird z. B. eingesetzt bei der Integration von Datenbanken in eine Data-Warehouse-Lösung, bei der Replikation von Daten für Backup- oder Disaster-Recovery-Zwecke oder bei der Datenmigration zwischen verschiedenen Systemen. Das Muster kann ebenfalls verwendet werden, um eine Änderungshistorie aufzuzeichnen, was für Compliance-Zwecke hilfreich sein kann.
Transactional Outbox
Das Transactional Outbox Pattern ist ein Muster zur Gewährleistung der atomaren Konsistenz zwischen einer Hauptdatenbanktransaktion und der Veröffentlichung von Ereignissen oder Benachrichtigungen an externe Systeme oder Dienste. Bei diesem Muster werden die zu veröffentlichenden Ereignisse oder Benachrichtigungen in einer speziellen Datenstruktur, dem Outbox, innerhalb der gleichen Datenbanktransaktion gespeichert, die auch die Änderungen an den Daten in der Datenbank durchführt.
Nachdem die Datenbanktransaktion erfolgreich abgeschlossen wurde, werden die im Outbox gespeicherten Ereignisse oder Benachrichtigungen an den Messaging-Dienst gesendet, der sie dann an interessierte Empfänger weiterleitet.
Der entscheidende Vorteil des Transactional Outbox besteht darin, dass die Veröffentlichung von Ereignissen oder Benachrichtigungen an externe Systeme oder Dienste atomar mit der Datenbanktransaktion erfolgt. Dies stellt sicher, dass sowohl die Datenbanktransaktion als auch die damit verbundenen Veröffentlichungsaktionen entweder erfolgreich abgeschlossen werden oder vollständig zurückgesetzt werden, um Konsistenz sicherzustellen.
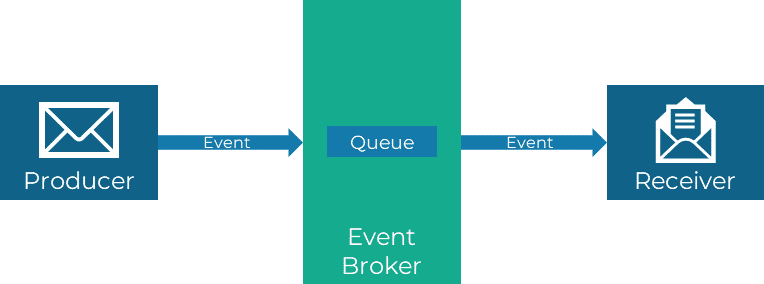
Point-to-Point
Point-to-Point-Verbindungen erlauben es, Nachrichten direkt an einen bestimmten Empfänger zu senden. Es handelt sich hierbei also um eine 1:1-Kommunikation. Innerhalb des Messaging-Systems wird dies oft mithilfe sogenannter Queues (Nachrichtenwarteschlangen) abgebildet.
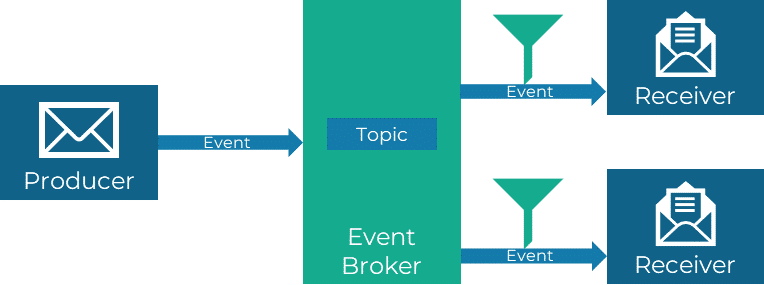
Publish/Subscribe
Publish/Subscribe ist wohl eines der bekanntesten Muster für ereignisbasierte Systeme. Bei diesem Muster gibt es zwei Hauptakteure: Publisher (Veröffentlicher) und Subscriber (Abonnenten). Publisher sind für das Erzeugen und Veröffentlichen von Nachrichten verantwortlich, während Subscriber sich registrieren, um bestimmte Nachrichten zu empfangen und darauf zu reagieren. Dadurch entsteht eine lose Kopplung zwischen den Publishern und Subscribern, da sie nicht direkt miteinander kommunizieren, sondern über den Broker agieren.
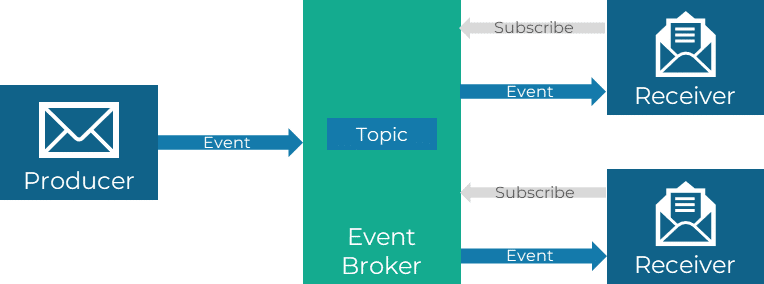
Bei typischen Messaging-Systemen wie Apache Kafka oder RabbitMQ können Nachrichten an spezifische „Topics“ oder „Channels“ gesendet werden. Subscriber können sich dann für den Empfang von Nachrichten zu diesen Topics oder Channels registrieren.
Request/Reply
Das Publish/Subscribe-Muster erlaubt nur einen unidirektionalen Nachrichtenversand. Wenn der Produzent an einer Antwort des Empfängers interessiert ist, kann stattdessen das Request/Reply-Muster eingesetzt werden. Das Request/Reply-Muster unterstützt eine synchronisierte und deterministische Kommunikation zwischen Produzenten und Empfänger. Dadurch erhält der Produzent sofort eine Rückmeldung, was besonders nützlich ist, wenn der Produzent auf die Ergebnisse der Anfrage angewiesen ist.
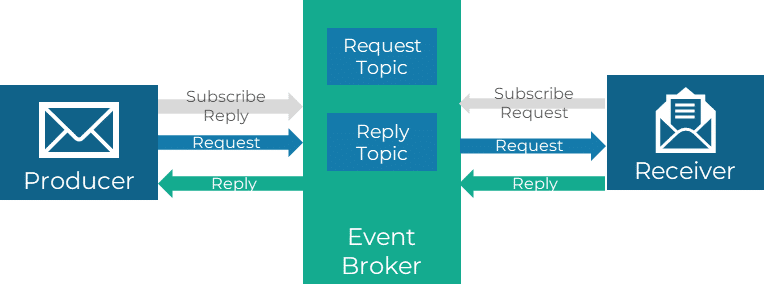
Typischerweise wird für die Umsetzung je ein Topic bzw. eine Queue für die Requests und Replys angelegt. Alternativ kann der Produzent bei der Anfrage eine Antwortadresse mitgeben, an die der Empfänger seine Rückmeldung schickt. Jedenfalls wird bei Request/Reply die Kommunikation über zwei eigenständige Nachrichten abgebildet: eine, die der Produzent für die Anfrage erzeugt und eine weitere, in die der Empfänger seine Antwort packt.
Event Mesh
Ein Event Mesh zielt darauf ab, die Kommunikation und den Austausch von Ereignissen zwischen verschiedenen Anwendungen, Diensten und Systemen in einer verteilten Umgebung zu erleichtern. Im Gegensatz zu anderen Übertragungsansätzen fungiert das Event Mesh als dezentrale, skalierbare und flexible Infrastruktur für die Ereignisverarbeitung.
Ein Event Mesh besteht aus einer Netzwerktopologie, in der verschiedene Knoten miteinander verbunden sind und Ereignisse über ein gemeinsames Nachrichtenübertragungsprotokoll austauschen können. Diese Knoten können beispielsweise Anwendungen, Dienste, Messaging-Broker oder andere Ereignisquellen sein. Durch die Verwendung eines Event Mesh wird die Kommunikation entkoppelt und es entsteht ein lose gekoppeltes Netzwerk von Ereignisverarbeitungsknoten.
Ein wesentlicher Vorteil des Event Mesh besteht darin, dass es eine hohe Skalierbarkeit und Flexibilität bietet. Neue Anwendungen oder Dienste können einfach in das Mesh integriert werden, ohne dass dies Auswirkungen auf die bestehende Infrastruktur hat. Darüber hinaus ermöglicht das Mesh eine effiziente Ereignisverarbeitung und -weiterleitung, da Ereignisse automatisch über das Netzwerk verteilt und an interessierte Empfänger weitergeleitet werden.
Guaranteed Delivery
Insbesondere bei kritischen Nachrichten kann das Guaranteed Delivery-Muster helfen, die Nachrichtenzustellung zu garantieren. Dabei wird eine Nachricht in einem lokalen Speicher und so lange gehalten, bis sie erfolgreich weiter geleitet wurde. Bei Übertragungsfehlern ist die Nachricht so immer noch im lokalen Speicher verfügbar.
Der Erhalt der Nachricht beim Empfänger kann über einen Bestätigungsmechanismus (Acknowledge) gesteuert werden. Im einfachsten Fall kann das ein Callback sein, welcher der Empfänger aufruft, sobald die Nachricht verarbeitet wurde. Der Produzent weiß dann, dass er die Nachricht aus dem lokalen Speicher wieder entfernen kann und die Zustellung erfolgreich war.
Event Filtering
Nicht alle Ereignisse, die über einen Event Broker geschickt werden, müssen für jeden Empfänger von Relevanz sein. Über Event Filtering kann ein Empfänger entscheiden, welche Nachrichten er empfangen und welche er ignorieren möchte.
Filter können typischerweise anhand von Metadaten der Ereignisse definiert werden. Der Event Broker leitet nur Nachrichten weiter, die den Filterkriterien entsprechen. Dies sorgt auch für eine ressourcenschonende Verarbeitung beim Empfänger, da keine unnötigen Ressourcen für das Auswerten der irrelevanten Ereignisse benötigt werden.
Dead Letter Queue
Die Dead Letter Queue wird verwendet, um mit fehlgeschlagenen oder unzustellbaren Nachrichten umzugehen. Eine Dead Letter Queue ist eine spezielle Warteschlange, in die Nachrichten verschoben werden, die aus verschiedenen Gründen nicht ordnungsgemäß verarbeitet werden können. Die Gründe hierfür können z. B. eine Zeitüberschreitung (bei Ablauf der Time-to-Life (TTL) einer Nachricht), unerwartete Nachrichtenformate oder ein unerwarteter Fehler bei der Verarbeitung sein.
Durch die Dead Letter Queue wird sicher gestellt, dass keine Nachrichten verloren gehen oder unbehandelt bleiben. Nachrichten, die nicht erfolgreich verarbeitet werden können, werden in die Dead Letter Queue verschoben, wo sie später untersucht und erneut verarbeitet werden können.
Darüber hinaus bietet die Dead Letter Queue auch eine Möglichkeit zur Fehleranalyse und Fehlerbehebung. Entwickler können die Nachrichten in der Dead Letter Queue überprüfen, um herauszufinden, warum sie nicht erfolgreich verarbeitet wurden und entsprechende Maßnahmen ergreifen, um die Ursachen des Problems zu beheben.
Saga
Das Saga-Muster wird zur Verwaltung und Koordination von verteilten Transaktionen in Systemen mit mehreren Diensten verwendet. Das Hauptziel einer Saga ist es, die atomare Konsistenz über mehrere Schritte oder Aktionen hinweg sicherzustellen, die in einer verteilten Umgebung ausgeführt werden. Eine Saga besteht aus einer Sequenz von Transaktionen, die eine Aktion in einem Service ausführt und ein Ereignis veröffentlich, um die nachfolgende Transaktion auszulösen. Im Fehlerfall führt die Saga Kompensationstransaktionen aus, die vorhergegangene Schritte rückgängig macht.
Ein typisches Beispiel für die Anwendung des Saga-Musters ist ein E-Commerce-System, bei dem eine Bestellung aufgegeben wird. Die Saga könnte mehrere Schritte umfassen, wie z. B. die Überprüfung der Lagerbestände, die Reservierung von Produkten, die Zahlungsabwicklung und den Versand. Wenn ein Schritt fehlschlägt, können die vorherigen Schritte rückgängig gemacht werden, um die Konsistenz des Systems wiederherzustellen.
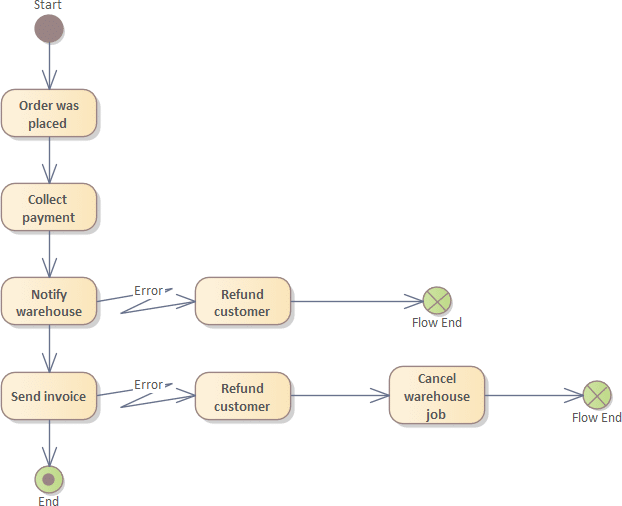
Herausforderungen können beim Debuggen auftreten, da der Status von mehreren Systemen im Auge behalten werden muss. Die Komplexität steigt mit jedem Teilnehmer in der Transaktionskette. Es empfiehlt sich, alle Schritte idempotent zu implementieren. Das bedeutet, dass der gleiche Funktionsaufruf mehrmals ausgeführt werden kann, ohne das Endergebnis zu verändern. Durch Idempotenz können Ereignisse bei Übertragungsfehler wiederholt werden, ohne Nebenwirkungen zu erzeugen.
Discard/Pause/Retry
Wenn bei der Verarbeitung von Nachrichten ein Fehler auftritt, gibt es folgende Möglichkeiten diese Fehler zu behandeln:
- Discard (Verwerfen): Die Nachricht wird verworfen und nicht mehr weiter behandelt. Diese Option ist nur für unkritische Nachrichten geeignet.
- Pause (Pausieren): Die Nachrichtenzustellung wird zwischenzeitlich pausiert und die Nachricht in einem sogenannten Retry-Buffer gehalten. Zu einem späteren Zeitpunkt wird die Nachrichtenverarbeitung nochmals wiederholt.
- Retry (Wiederholen): Die Nachrichtenverarbeitung wird sofort oder nach einer bestimmten Wartezeit noch einmal wiederholt. Falls nach einer bestimmten Zahl von Wiederholungsvorgängen die Verarbeitung immer noch fehlschlägt, kann die Nachricht verworfen oder pausiert werden.
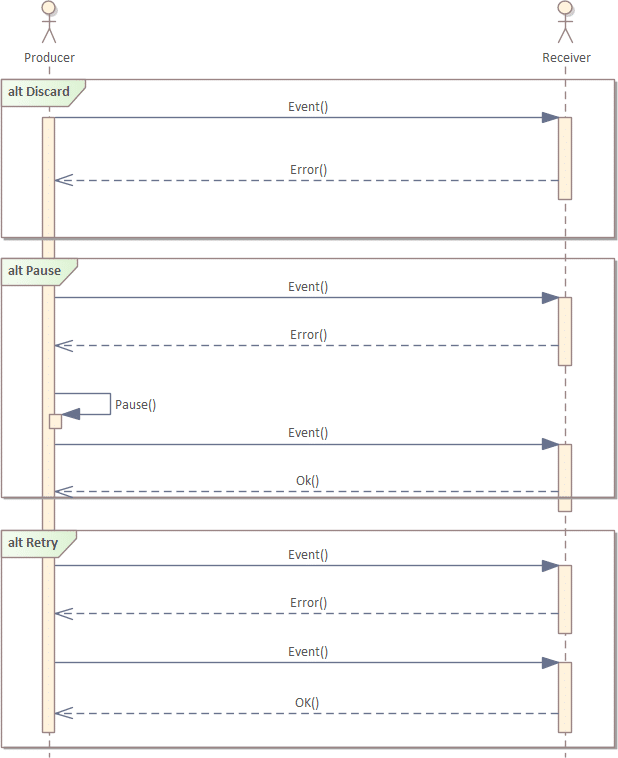
Diess Pattern hilft flexibel mit Fehlerzuständen umzugehen. Weiters kann durch die unterschiedlichen Fehlerbehandlungsansätze eine Priorisierung der Nachrichten erreicht werden.
Weitere Muster
Neben den genannten Mustern gibt es noch eine Vielzahl weitere. Empfehlenswerte weitere Quellen sind hierzu die Cloud Design Patterns des Azure Architecture Center oder die Pattern Language for Microservices von Microservices.io.
Best Practices
Für den effektiven Einsatz von ereignisgesteuerten Architekturen sollten einige bewährte Praktiken beachtet werden. Im Folgenden sind einige Best Practices aufgeführt, die bei der Gestaltung und Implementierung ereignisgesteuerter Architekturen berücksichtigt werden sollten.
Definition der Ereignisse
Beginnen Sie mit einer klaren Definition der Ereignisse, die in Ihrem System auftreten können. Identifizieren Sie die wichtigsten Ereignisse, die für Ihre Anwendung relevant sind, und definieren Sie deren Struktur und Eigenschaften. Eine klare Definition der Ereignisse bildet die Grundlage für das Design und die Implementierung Ihrer ereignisgesteuerten Architektur.
Gegebenenfalls kann Ihnen die Unterscheidung zwischen Domain und Integrations Events helfen. Domain Events sind Ereignisse, die innerhalb eines bestimmten Bounded Contexts auftreten und die Veränderungen oder Aktionen innerhalb dieses begrenzten Kontexts darstellen. Sie erfassen bedeutsame Zustandsänderungen innerhalb des Domänenmodells und sind deshalb oft eng mit der Fachlichkeit der Anwendung verbunden. Integration Events hingegen sind Ereignisse, die über die Grenzen eines Bounded Contexts hinausgehen und zur Integration mehrerer Contexts dienen. Sie dienen der systemübergreifenden Kommunikation und Koordination, weshalb sie weniger domänenspezifisch sind.
Monitoring und Logging
Implementieren Sie umfassendes Monitoring und Logging für Ihre ereignisgetriebene Architektur, um die Leistung, Verfügbarkeit und Zuverlässigkeit des Systems zu überwachen. Insbesondere die Fehlersuche kann sich als schwierig gestalten, wenn hierzu keine Maßnahmen getroffen wurden. Verwenden Sie geeignete Tools und Technologien, um Metriken und Protokolle zu sammeln, und analysieren Sie diese regelmäßig, um potenzielle Engpässe oder Probleme frühzeitig zu erkennen und zu beheben.
Monitoring und Logging sollten vor allem schon während der Entwicklung fest eingeplant werden und nicht erst im Bedarfsfall nachgezogen werden. Dies ist nämlich auch eine wichtige Grundlage für den nächsten Tipp.
Testing
Der größte Unterschied zwischen einer EDA und einer konventionellen Anwendung ist die asynchrone Natur der Ereignisse. Dies erfordert neben den typischen Tests noch weitere, umfangreiche zusätzliche Tests, welche beispielsweise Verzögerung bei der Ereigniszustellung, Kompensationsaktionen, Nebenläufigkeit oder Race-Conditions berücksichtigen müssen.
Insbesondere sollte auch dem System-Integration-Testing eine besondere Beachtung geschenkt werden. Hier wird sichergestellt, dass die verschiedenen verteilten Komponenten der EDA über den Event-Broker korrekt integrieren.
Lose Kopplung
Eine der Schlüsselprinzipien einer EDA ist die lose Kopplung zwischen den Komponenten. Vermeiden Sie es deshalb auf anderem Wege, direkte Abhängigkeiten zwischen den Komponenten zu bekommen und nutzen Sie ausschließlich den Event-Broker, um Nachrichten zwischen den Komponenten auszutauschen. Dadurch bleibt das System flexibel und skalierbar.
Rückfallmechanismen
Eine der Fallacies of Distributed Computing besagt, dass das Netzwerk nicht immer stabil ist. Es wird zwangsläufig zu Ausfällen und Unterbrechungen in der Netzwerkkommunikation kommen. Stellen Sie daher sicher, dass Ihr System mit diesen Ausfällen umgehen kann, indem Sie Rückfallmechanismen implementieren. Verwenden Sie beispielsweise Dead Letter Queues, um fehlgeschlagene Nachrichten zu behandeln, oder implementieren Sie Kompensationsaktionen in Ihren Szenarien, um Fehler zu beheben und die Konsistenz des Systems wiederherzustellen.
Abschluss
Ereignisgetriebene Architekturen können geeignet sein, um lose gekoppelte, skalierbare Systeme zu erzeugen. Die Komplexität sollte aber nicht unterschätzt werden. Deswegen gilt es die Vor- und Nachteile einer EDA gut abzuwägen.
Ob eine ereignisgetriebe Architektur für Ihren Einsatzzweck gut geeignet ist und wie sie am besten die Umsetzung angehen, können wir gerne bei einem Beratungsgespräch klären.
